A fast-growing Next.js site lost more than 90% of its organic traffic almost overnight after a design revamp.
We traced the collapse to a single line in the robots.txt file, restored traffic within days, and then fixed the underlying rendering issue that was hurting the site in both Google and AI search.
Our client’s organic traffic had been climbing steadily for months, then it fell off a cliff within a couple of days of a routine design update. By the time they came to us, they had lost more than 90% of their daily organic visitors and had spent close to three weeks trying to resolve it.
In this case study, we break down how we diagnosed the drop and helped them recover their organic traffic.
About the Client
Our client runs a leading online platform in India’s devotional and religious services space. The platform lets users book verified, experienced pandits online for pujas, homas (havans), weddings, griha pravesh, and other ceremonies and rituals.
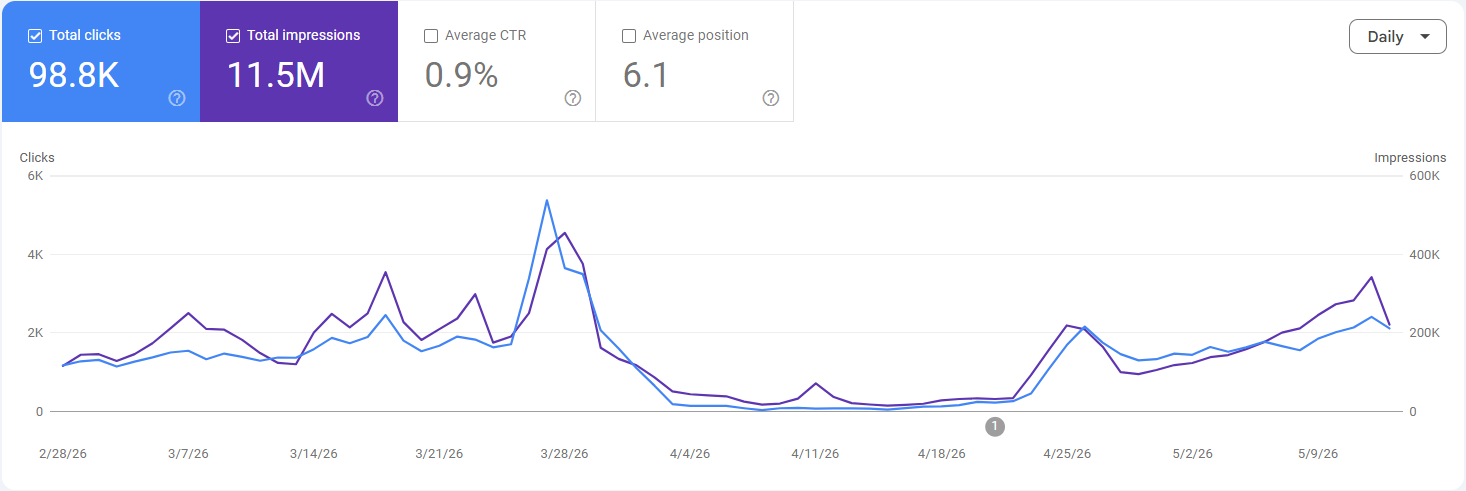
Organic search was a major channel for the platform, bringing in traffic across both its service pages and its blog, with daily visits growing steadily to a peak of around 5,000. The site was built on Next.js, with its pages rendered on the client side.
Challenges Faced
The client’s team came to us with a clear and urgent problem.
- Organic traffic had dropped from a peak of 5,000 visits down to roughly 200, a decline of more than 90%.
- The collapse happened within a couple of days of a new design going live on key service pages.
- The site had been bleeding traffic for around 20 days before they engaged us.
- Their in-house team could not identify the cause, and the pages looked completely normal when opened in a browser.
- The site was built on Next.js with client-side rendering, which meant the problem was not visible through a standard content review.
Our Approach
1. Crawl and Render Diagnosis
Since the website was built on Next.js, we started off by checking whether Google could actually see the pages.
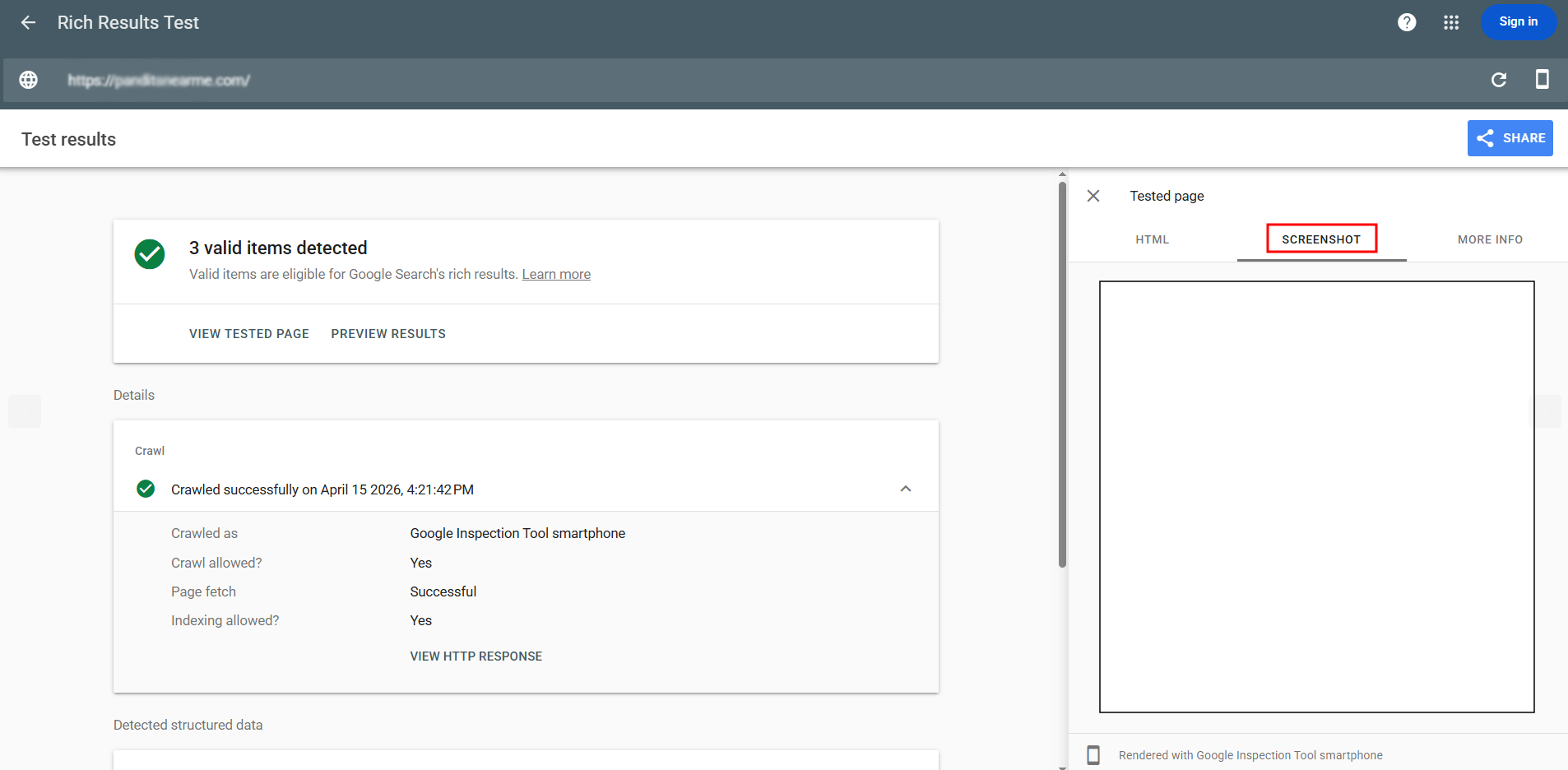
We ran the affected URLs through Google’s Rich Results Test, which shows a screenshot of the page exactly as Googlebot renders it. Instead of the live page, we got a plain white blank screen.
For a site whose content is built with JavaScript, a blank render is a strong signal that Google was unable to load the resources it needed to build the page. The content was there for users, but not for Google.
2. Robots.txt Audit
A blank render on a JavaScript site usually points to blocked resources, so we went straight to the robots.txt file.
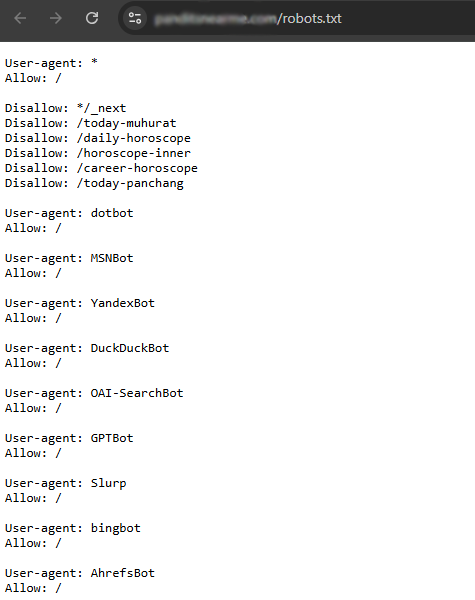
In a Next.js site, all of the compiled JavaScript and CSS that builds the page is served from a folder called /_next/.
We found that during the redesign, the development team had accidentally added a temporary rule disallowing this folder to all crawlers and missed removing it:
Disallow: /_next/
This was the root cause.

The Disallow: /_next/ line told Google it was not allowed to crawl and index files within /_next/.
Now, all the important page content was inside /_next/, which made the entire page invisible to Google.
With nothing to show, Google dropped the pages from its search results, and the traffic went with them.
Recover the Traffic You Lost
Sudden ranking drops are rarely random; algorithm updates, technical issues, or content decay are quietly eating your traffic. Our traffic drop analysis pinpoints the exact cause and gives you a clear recovery plan.
3. Coordinating the Fix and Confirming Recovery
We flagged the rule to the client’s development team, who removed it immediately.
We then re-ran the Rich Results Test to confirm that Googlebot could once again fetch the files and render the full page. With the resources unblocked, the pages rendered correctly, and Google was able to crawl and re-index the real content.
With the crawling and indexing issue resolved, we did not stop at the quick win. A traffic drop of this scale is often a symptom of a more fundamental rendering setup, so we audited how the site was serving its content to search engines.
We noticed that across the site, Google was displaying the raw URL as the clickable title in search results, with no meta description showing beneath it. This is the classic sign of a site whose titles, description, and entire page content are generated by client-side rendering.
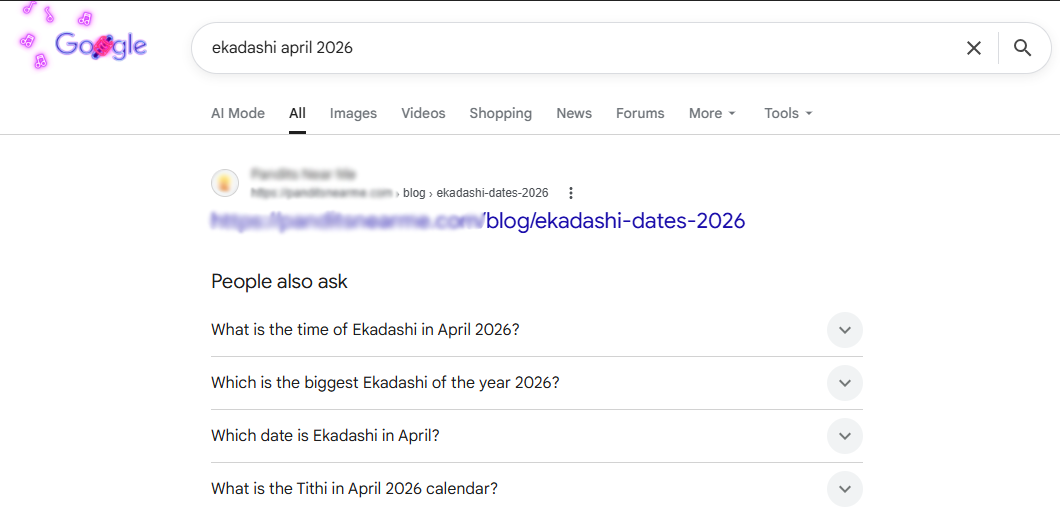
We validated this by viewing the page source, the raw HTML before any JavaScript executes. The title tag, the meta description, and the body content were all absent. Everything was being generated on the client side, which meant Google had nothing reliable to read on first contact.

Google can render JavaScript in a second indexing pass, so in theory it can pick up client-side titles eventually. But that rendering is delayed, not guaranteed, and limited by render budget, which is why anything critical should never depend on it. In this case, Google was clearly falling back to the URL because it could not find a usable title in what it had indexed.
4. Server-Side Rendering Migration
Our recommendation was to move the critical elements- the title, meta description, headings, and body content- to server-side rendering, so that they are present in the initial HTML response that every crawler receives.
This mattered for two reasons:
- Google Reliability:
- Server-rendered content removes the dependency on Google’s render budget and ensures titles, descriptions, and content are indexed correctly on first crawl.
- LLMs Search Visibility:
- This is the point that is often missed. AI crawlers do not behave like Googlebot. GPTBot, ClaudeBot, and PerplexityBot do not execute JavaScript at all. They fetch the raw HTML, take what is there, and move on.
- A site that renders everything on the client side is therefore not just risky for Google; it is completely invisible to ChatGPT, Claude, and Perplexity. Moving content to server-side rendering was what made the site eligible to appear in AI-generated answers in the first place.
The client implemented server-side rendering with this recommendation.
Implementation Timeline
The client’s site had been losing traffic for around 20 days before they engaged us. We diagnosed the blocked /_next/ folder on the first day of the audit; the development team removed the rule straight away, and organic traffic returned to its previous baseline within a couple of days.
In parallel, we audited the site’s rendering setup, identified the client-side rendering issue behind the URL-as-title problem, and the client moved their critical content and metadata to server-side rendering on our recommendation.
Results Achieved
- Rapid recovery within days: Organic traffic climbed back from roughly 200 daily visits to around 3,500 within a couple of days of the robots.txt fix, reversing the bulk of the 90%+ collapse, with volumes still trending up.
- Correct titles and descriptions restored: After the move to server-side rendering, page titles and meta descriptions appeared correctly in the raw HTML, resolving the URL-as-title display and the empty snippets across the site.
- Visibility to AI search engines: With content served in the initial HTML, the site became readable by AI crawlers that ignore JavaScript, restoring its eligibility to be cited in AI-generated answers as well as traditional search.
Conclusion
A site can be perfectly designed, fast, and full of good content for its visitors, and still be invisible to search engines if the technical setup gets in the way. In this case, a single misplaced line in a robots.txt file took down more than 90% of a Next.js site’s organic traffic, and a deeper client-side rendering issue was quietly limiting how the site appeared in both Google and AI search.
The lesson for any business on a JavaScript framework is the same one this recovery demonstrates. Always check what the crawler sees, not just what the browser shows, and make sure your critical content lives in the initial HTML so that Google and the new generation of AI crawlers can read it.
If your site runs on Next.js, React, or any JavaScript framework and your traffic has dropped or never reflected the quality of your content, Growffic can find out why. We offer Organic SEO services and Generative Engine Optimization services to make sure you are visible across both traditional search and AI-driven discovery.
Build High-Value Search Traffic
Stop relying on paid ads that drain budget the moment you pause them. Our organic SEO services build compounding rankings, qualified traffic, and revenue that keeps growing month after month.